What is Haystack?
Haystack is the open source Python framework by deepset for building custom apps with large language models (LLMs). It lets you quickly try out the latest models in natural language processing (NLP) while being flexible and easy to use. Our inspiring community of users and builders has helped shape Haystack into what it is today: a complete framework for building production-ready NLP apps.
Building with Haystack
Haystack offers comprehensive tooling for developing state-of-the-art NLP systems that use LLMs (such as GPT-4, Falcon and similar) and Transformer models . With Haystack, you can effortlessly experiment with various models hosted on platforms like Hugging Face, OpenAI, Cohere, or even models deployed on SageMaker and your local models to find the perfect fit for your use case.
Some examples of what you can build include:
- Semantic search on a large collection of documents in any language
- Generative question answering on a knowledge base containing mixed types of information: images, text, and tables.
- Natural language chatbots powered by cutting-edge generative models like GPT-4
- An LLM-based Haystack Agent capable of resolving complex queries
- Information extraction from documents to populate your database or build a knowledge graph
This is just a small subset of the kinds of systems that can be created in Haystack.
Functionality for all stages of an NLP project
A successful NLP project requires more than just the language models. As an end-to-end framework, Haystack assists you in building your system every step of the way, offering tooling for each stage of the NLP project life cycle:
- Effortless deployment of models from Hugging Face or other providers into your NLP pipeline
- Create dynamic templates for LLM prompting
- Cleaning and preprocessing functions for various formats and sources
- Seamless integrations with your preferred document store (including many popular vector databases like Faiss, Pinecone, Qdrant, or Weaviate): keep your NLP-driven apps up-to-date with Haystack’s indexing pipelines that help you prepare and maintain your data
- The free annotation tool for a faster and more structured annotation process
- Tooling for fine-tuning a pre-trained language model
- Specialized evaluation pipelines that use different metrics to evaluate the entire system or its individual components
- Haystack’s REST API to deploy your final system so that you can query it with a user-facing interface
But that’s not all: metadata filtering, model distillation, or the prompt hub, whatever your NLP heart desires, you’re likely to find it in Haystack. And if not? We’ll build it together.
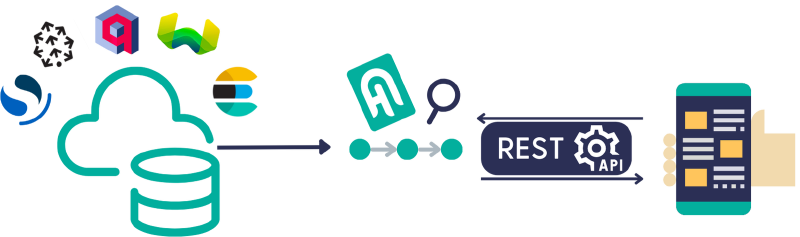
Building blocks
Haystack uses a few simple but effective concepts to help you build fully functional and customized end-to-end NLP systems.
Components
At the core of Haystack are its components—fundamental building blocks that can perform tasks like document retrieval, text generation, or summarization. A single component is already quite powerful. It can manage local language models or communicate with a hosted model through an API.
While Haystack offers a bunch of components you can use out of the box, it also lets you create your own custom components. Explore the collection of integrations that includes custom components developed by our community, which you can freely use.
You can chain components together to build pipelines, which are the foundation of the NLP app architecture in Haystack.
Pipelines
Pipelines are powerful structures made up of components, such as a Retriever and Reader, connected to infrastructure building blocks, such as a DocumentStore (for example, Elasticsearch or Weaviate) to form complex systems.
Haystack offers ready-made pipelines for most common tasks, such as question answering, document retrieval, or summarization. But it’s just as easy to design and create a custom pipeline for NLP scenarios that are way more complex than question answering.
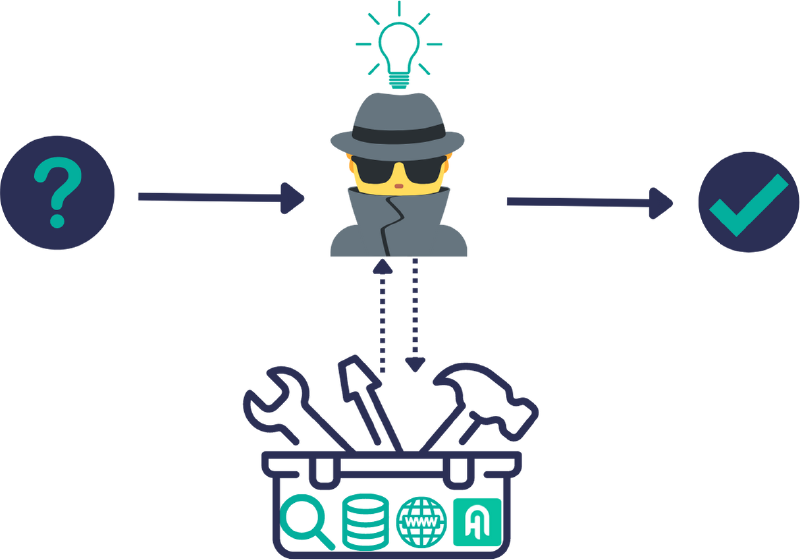
Agents
The Haystack Agent makes use of a large language model to resolve complex tasks. When initializing the Agent, you give it a set of tools, which can be pipeline components or whole pipelines. The Agent can use to those tools iteratively to arrive at an answer. When given a query, the Agent determines which tools are useful to answer this query and calls them in a loop until it gets the answer. This way, it can achieve much more than extractive or generative question answering pipelines.
Who’s it for?
Haystack is for everyone looking to build natural language apps—NLP enthusiasts and newbies alike. You don’t need to understand how the models work under the hood. With Haystack’s modular and flexible components, pipelines, and agents, all you need is some basic knowledge of Python to dive right in.
Our community
At the heart of Haystack is the vibrant open source community that thrives on the diverse backgrounds and skill sets of its members. We value collaboration greatly and encourage our users to shape Haystack actively through GitHub contributions. Our Discord channel is a space where community members can connect, seek help, and learn from each other.
We also organize live online and in-person events, webinars, and office hours, which are an opportunity to learn and grow.
Enter the Haystack universe
- Visit our GitHub repo
- Start building with tutorials in Colab notebooks
- Have a look at the documentation
- Read and contribute to our blog