

Lufthansa Industry Solutions Uses Haystack to Power Enterprise RAG
Learn how Lufthansa Industry Solutions (LHIND) built an enterprise-grade, compliant AI knowledge assistant
October 24, 2025When you think of Lufthansa, you might picture planes, airports, or global travel, but Lufthansa Industry Solutions (LHIND) is making an impact in a different way: as a full-service IT company delivering digital solutions for clients both inside and outside the Lufthansa Group.
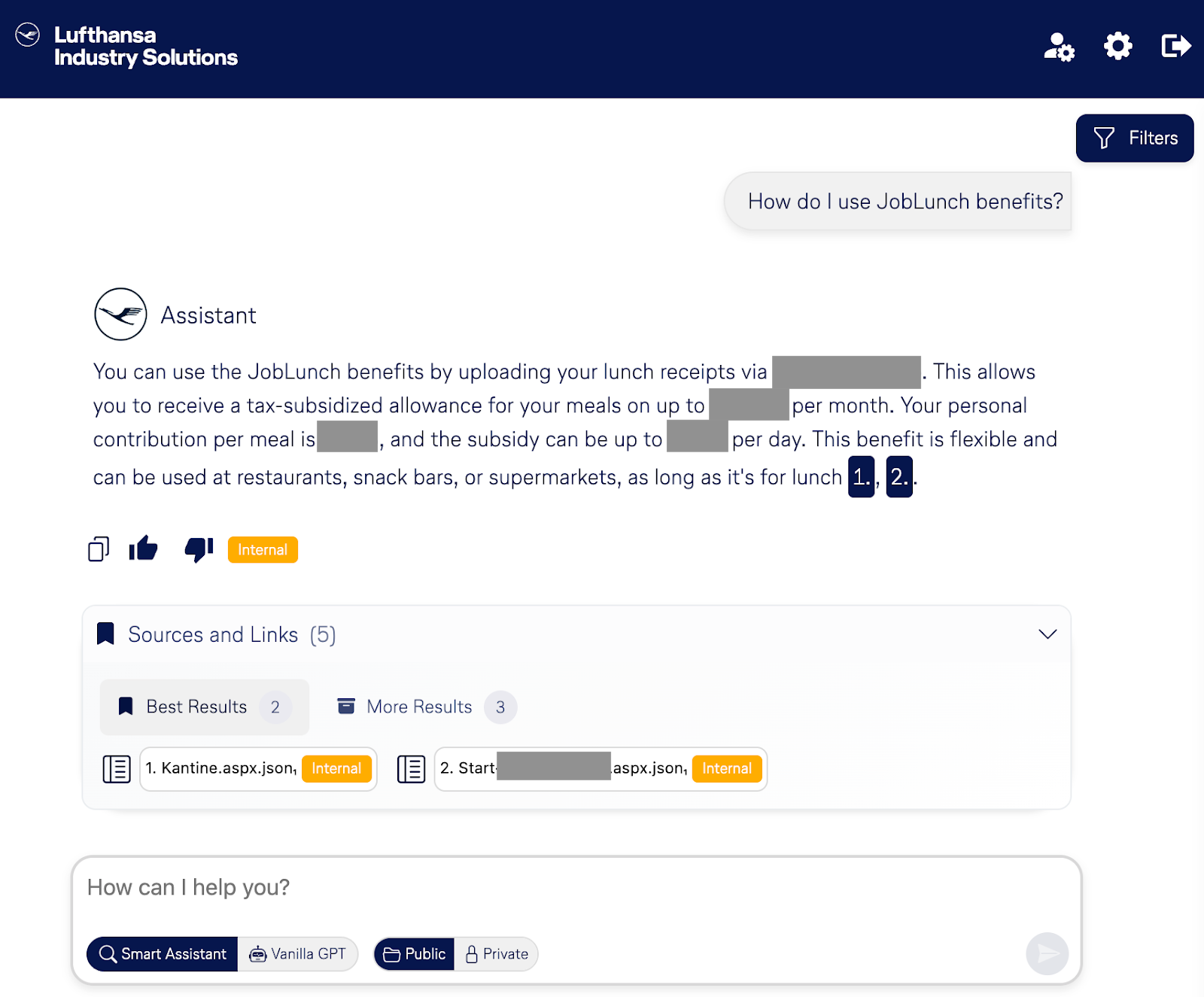
At LHIND, a subsidiary of the Lufthansa Group, teams work on a wide range of projects that span cloud infrastructure, AI, and enterprise data systems to custom software development, process automation, and digital transformation initiatives. Among them is SmartAssistantAI, an enterprise AI chatbot implementation to make company knowledge accessible to everyone, instantly and securely.
Behind the product is Nils Hilgers, Lead AI Engineer at LHIND and his team of engineers and product builders. Together, they’re rethinking enterprise search through the lens of retrieval-augmented generation (RAG) and enterprise-grade security standards.
To bring that vision to life, the team selected Haystack as one of their key solutions for powering their AI Assistant.
The Challenge: Connecting Scattered Knowledge
LHIND’s engineering group was tasked with building a secure, centralized assistant capable of answering employees’ questions using the company’s internal documentation. The challenge wasn’t just accuracy — it was compliance and control.
The system needed to:
- Handle multiple data sources (SharePoint, internal wikis etc.)
- Operate under GDPR, ISO 27001, and Lufthansa Group’s own IT governance standards
- Deliver explainable, source-cited results
With a small team of developer and engineers working in an agile setup, supported by a dedicated platform team, they set out to design a solution that could unify data retrieval and LLM-based reasoning without sacrificing traceability or maintainability.
Choosing Haystack: Flexibility Meets Stability
When the project began, the team evaluated several orchestration frameworks to structure their RAG pipelines. They needed something reliable enough for production but flexible enough to adapt as requirements evolved.
“We needed a graph orchestration framework with well-thought fundamentals that is stable for production” says Nils.
After testing a few alternatives, Haystack stood out for:
- Orchestration layer built on directed graphs with easy serialization and visualization
- Unified filtering across different vector database providers
- Jinja-based prompt templating, which made their prompts more maintainable
Having used the older 1.x REST API for some demos, the team already knew Haystack’s foundations and migrating to 2.x resulted in cleaner, more maintainable code.
The Technical Architecture: How It All Comes Together
The assistant is a cloud-native, microservice-based system built around modularity and open-source principles. It combines Haystack pipelines with custom middleware and observability tooling. It’s not a public-facing product, rather, a secure solution deployed in enterprise environments where control over data and access is critical.
Core Components
1. Frontend and Authentication
A modular frontend built with microfrontends allows different configurations per customer like custom stylesheet, logo, and login interfaces through an admin interface. A Golang-based authentication middleware enforces role-based access control (RBAC) and ensures user permissions are respected end-to-end.
2. Ingestion Pipelines
Data ingestion is built on Haystack pipelines, with a custom data integration protocol. For preprocessing, domain-specific tools with Haystack OCR and custom converters. The custom data integration protocol includes the periodic LEFT-JOIN-style synchronization that removes outdated or deleted entries using hashing logic, allowing customers to synchronize their niche data source into the vector database.
3. Query Services
At the heart of the system, FastAPI-based query services integrate directly with Haystack pipelines. A ConditionalRouter directs requests to either a general LLM (GPT models) or a RAG pipeline, depending on the nature of the question.
Before the retrieval step, the assistant performs query rewriting based on the ongoing chat history, rephrasing the user’s question to optimize for hybrid search and ensure more accurate context retrieval.
Using server-sent events (SSE), the system streams results in real time and provides full transparency into the generation process: showing the routed and rewritten queries, the matched documents, and the final LLM-generated answer.
4. Observability and Monitoring
To monitor performance and reliability, the team integrated Langfuse for observability and Grafana + Kubernetes for operational monitoring. These tools save every incoming query and feedback in the data warehouse for future analysis and evaluation.
Measuring Success: From Latency to Feedback Loops
Rather than focusing on flashy metrics, the team prioritized efficiency and feedback quality. Their success criterion was simple: reduce the time it takes for people to find what they need.
Since that’s hard to measure directly, they rely on a mix of proxy metrics:
- Usage metrics: daily and unique request counts across customers
- Latency: time-to-first-token and time-to-last-token, especially 90th percentile
- User feedback: thumbs-up/down and open-text comments
💡 Negative feedback with detailed comments has proven especially valuable, enabling developers to use observability tools to trace whether an issue stems from prompting, retrieval, or data quality.
Lessons Learned: Build Quality Early, Iterate Fast
Nils emphasizes a pragmatic approach: software quality and observability are not afterthoughts; they are foundations.
“Focus on engineering quality early, even if it slows you down,” he advises.
The team learned that robust infrastructure and documentation pay off in the long run, even if setup takes longer initially.
They emphasize:
- Lean container builds and fast CI/CD pipelines
- Clear internal documentation of database schemas, roles, and dependencies
- Human-annotated evaluation datasets to track the performance of different iterations over model and prompt adjustments
Their development process combines disciplined engineering with agile experimentation, a balance that keeps the project moving fast without sacrificing reliability.
What’s Next
The roadmap for the coming quarters focuses on enhancing data integration and observability:
- Migrating to a ClickHouse warehouse to handle growing data volumes efficiently
- Adding server-side prompt management for version control
Further plans include:
- Time-aware ranking to eliminate outdated knowledge
- Deeper Integrations with Atlassian tools, relational databases, and CRM systems
- A cleaner architecture using Haystack’s newer abstractions, like SuperComponents
The next step is scaling both quality and speed while still keeping the system easy to maintain.
Share Your Story with Us
LHIND’s journey shows how Haystack empowers developers to build reliable, customizable, and compliant AI assistants at enterprise scale, like SmartAssistantAI. Get started with Haystack and build your own intelligent, trustworthy assistants for enterprise knowledge access.
We know there are many more stories like this out there. If your team has built something exciting with Haystack, whether it’s a chatbot, a retrieval system, an agent, or an AI-powered internal tool, get in touch with us. We’d love to feature your work and share how you’re shaping the future with Haystack.

