
Creating Pipelines
Learn the general principles of creating a pipeline.
You can use these instructions to create both indexing and query pipelines.
This task uses an example of a semantic document search pipeline.
Prerequisites
For each component you want to use in your pipeline, you must know the names of its input and output. You can check them on the documentation page for a specific component or in the component's run() method. For more information, see Components: Input and Output.
Steps to Create a Pipeline
1. Import dependencies
Import all the dependencies, like Pipeline, Documents, Document Store, and all the components you want to use in your pipeline.
For example, to create a semantic document search pipelines, you need the Document object, the Pipeline, the Document Store, Embedders, and a Retriever:
from haystack import Document, Pipeline
from haystack.document_stores.in_memory import InMemoryDocumentStore
from haystack.components.embedders import SentenceTransformersTextEmbedder
from haystack.components.retrievers.in_memory import InMemoryEmbeddingRetriever
2. Initialize components
Initialize the components, passing any parameters you want to configure:
document_store = InMemoryDocumentStore(embedding_similarity_function="cosine")
text_embedder = SentenceTransformersTextEmbedder()
retriever = InMemoryEmbeddingRetriever(document_store=document_store)
3. Create the Pipeline
query_pipeline = Pipeline()
4. Add components
Add components to the Pipeline one by one. The order in which you do this doesn't matter:
query_pipeline.add_component("component_name", component_type)
# Here is an example of how you'd add the components initialized in step 2 above:
query_pipeline.add_component("text_embedder", text_embedder)
query_pipelne.add_component("retriever", retriever)
# You could also add components without initializing them before:
query_pipeline.add_component("text_embedder", SentenceTransformersTextEmbedder())
query_pipeline.add_component("retriever", InMemoryEmbeddingRetriever(document_store=document_store))
5. Connect components
Connect the components by indicating which output of a component should be connected to the input of the next component. If a component has only one input or output and the connection is obvious, you can just pass the component name without specifying the input or output.
# This is the syntax to connect components. Here you're connecting output1 of component1 to input1 of component2:
pipeline.connect("component1.output1", "component2.input1")
# If both components have only one output and input, you can just pass their names:
pipeline.connect("component1", "component2")
# If one of the components has only one output but the other has multiple inputs,
# you can pass just the name of the component with a single output, but for the component with
# multiple inputs, you must specify which input you want to connect
# Here, component1 has only one output, but component2 has mulitiple inputs:
pipeline.connect("component1", "component2.input1")
# And here's how it should look like for the semantic document search pipeline we're using as an example:
query_pipeline.connect("text_embedder.embedding", "retriever.query_embedding")
# Because the InMemoryEmbeddingRetriever only has one input, this is also correct:
query_pipeline.connect("text_embedder.embedding", "retriever")
You need to link all the components together, connecting them gradually in pairs. Here's a more explicit example:
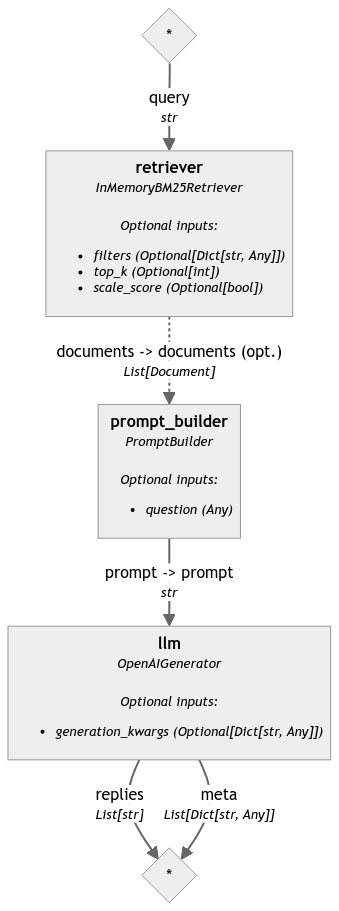
# Imagine this pipeline has four components: text_embedder, retriever, prompt_builder and llm.
# Here's how you would connect them into a pipeline:
pipeline.connect("text_embedder.embedding", "retriever")
pipeline.connect("retriever","prompt_builder.documents")
pipeline.connect("prompt_builder", "llm")
6. Run the Pipeline
Wait for the pipeline to validate the components and connections. If everything is OK, you can now run the pipeline. Pipeline.run() can be called in two ways, either passing a dictionary of the component names and their inputs, or by directly passing just the inputs. When passed directly, the pipeline resolves inputs to the correct components.
# Here's one way of calling the run() method
results = pipeline.run({"component1": {"input1_value": value1, "input2_value": value2}})
# The inputs can also be passed directly without specifying component names
results = pipeline.run({"input1_value": value1, "input2_value": value2})
# This is how you'd run the semantic document search pipeline we're using as an example:
query = "Here comes the query text"
results = query_pipeline.run({"text_embedder": {"text": query}})
Example
This recipe walks you through creating a RAG pipeline, explaining the code:
Here is what an output Mermaid graph of this pipeline looks like:
Updated 19 days ago