
Tutorial: Evaluating RAG Pipelines
Last Updated: August 25, 2025
- Level: Intermediate
- Time to complete: 15 minutes
- Components Used:
InMemoryDocumentStore,InMemoryEmbeddingRetriever,ChatPromptBuilder,OpenAIChatGenerator,DocumentMRREvaluator,FaithfulnessEvaluator,SASEvaluator - Prerequisites: You must have an API key from an active OpenAI account as this tutorial is using the gpt-4o-mini model by OpenAI: https://platform.openai.com/api-keys
- Goal: After completing this tutorial, you’ll have learned how to evaluate your RAG pipelines both with model-based, and statistical metrics available in the Haystack evaluation offering. You’ll also see which other evaluation frameworks are integrated with Haystack.
Overview
In this tutorial, you will learn how to evaluate Haystack pipelines, in particular, Retriaval-Augmented Generation ( RAG) pipelines.
- You will first build a pipeline that answers medical questions based on PubMed data.
- You will build an evaluation pipeline that makes use of some metrics like Document MRR and Answer Faithfulness.
- You will run your RAG pipeline and evaluated the output with your evaluation pipeline.
Haystack provides a wide range of
Evaluators which can perform 2 types of evaluations:
We will use some of these evalution techniques in this tutorial to evaluate a RAG pipeline that is designed to answer questions on PubMed data.
🧑🍳 As well as Haystack’s own evaluation metrics, you can also integrate with a number of evaluation frameworks. See the integrations and examples below 👇
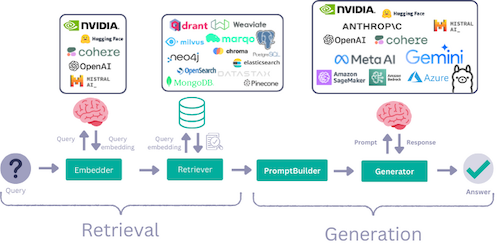
Evaluating RAG Pipelines
RAG pipelines ultimately consist of at least 2 steps:
- Retrieval
- Generation
To evaluate a full RAG pipeline, we have to evaluate each of these steps in isolation, as well as a full unit. While retrieval can in some cases be evaluated with some statistical metrics that require labels, it’s not a straight-forward task to do the same for the generation step. Instead, we often rely on model-based metrics to evaluate the generation step, where an LLM is used as the ’evaluator'.
📺 Code Along
Preparing the Colab Environment
Installing Haystack
Install Haystack and
datasets with pip:
%%bash
pip install haystack-ai
pip install "datasets>=2.6.1"
pip install "sentence-transformers>=4.1.0"
Create the RAG Pipeline to Evaluate
To evaluate a RAG pipeline, we need a RAG pipeline to start with. So, we will start by creating a question answering pipeline.
💡 For a complete tutorial on creating Retrieval-Augmmented Generation pipelines check out the Creating Your First QA Pipeline with Retrieval-Augmentation Tutorial
For this tutorial, we will be using a labeled PubMed dataset with questions, contexts and answers. This way, we can use the contexts as Documents, and we also have the required labeled data that we need for some of the evaluation metrics we will be using.
First, let’s fetch the prepared dataset and extract all_documents, all_questions and all_ground_truth_answers:
ℹ️ The dataset is quite large, we’re using the first 1000 rows in this example, but you can increase this if you want to
from datasets import load_dataset
from haystack import Document
dataset = load_dataset("vblagoje/PubMedQA_instruction", split="train")
dataset = dataset.select(range(1000))
all_documents = [Document(content=doc["context"]) for doc in dataset]
all_questions = [doc["instruction"] for doc in dataset]
all_ground_truth_answers = [doc["response"] for doc in dataset]
Next, let’s build a simple indexing pipeline and write the documents into a DocumentStore. Here, we’re using the InMemoryDocumentStore.
InMemoryDocumentStoreis the simplest DocumentStore to get started with. It requires no external dependencies and it’s a good option for smaller projects and debugging. But it doesn’t scale up so well to larger Document collections, so it’s not a good choice for production systems. To learn more about the different types of external databases that Haystack supports, see DocumentStore Integrations.
from typing import List
from haystack import Pipeline
from haystack.components.embedders import SentenceTransformersDocumentEmbedder
from haystack.components.writers import DocumentWriter
from haystack.document_stores.in_memory import InMemoryDocumentStore
from haystack.document_stores.types import DuplicatePolicy
document_store = InMemoryDocumentStore()
document_embedder = SentenceTransformersDocumentEmbedder(model="sentence-transformers/all-MiniLM-L6-v2")
document_writer = DocumentWriter(document_store=document_store, policy=DuplicatePolicy.SKIP)
indexing = Pipeline()
indexing.add_component(instance=document_embedder, name="document_embedder")
indexing.add_component(instance=document_writer, name="document_writer")
indexing.connect("document_embedder.documents", "document_writer.documents")
indexing.run({"document_embedder": {"documents": all_documents}})
Now that we have our data ready, we can create a simple RAG pipeline.
In this example, we’ll be using:
-
InMemoryEmbeddingRetrieverwhich will get the relevant documents to the query. -
OpenAIChatGeneratorto generate answers to queries. You can replaceOpenAIChatGeneratorin your pipeline with anotherChatGenerator. Check out the full list of generators here.
import os
from getpass import getpass
from haystack.components.builders import AnswerBuilder, ChatPromptBuilder
from haystack.dataclasses import ChatMessage
from haystack.components.embedders import SentenceTransformersTextEmbedder
from haystack.components.generators.chat import OpenAIChatGenerator
from haystack.components.retrievers.in_memory import InMemoryEmbeddingRetriever
if "OPENAI_API_KEY" not in os.environ:
os.environ["OPENAI_API_KEY"] = getpass("Enter OpenAI API key:")
template = [
ChatMessage.from_user(
"""
You have to answer the following question based on the given context information only.
Context:
{% for document in documents %}
{{ document.content }}
{% endfor %}
Question: {{question}}
Answer:
"""
)
]
rag_pipeline = Pipeline()
rag_pipeline.add_component(
"query_embedder", SentenceTransformersTextEmbedder(model="sentence-transformers/all-MiniLM-L6-v2")
)
rag_pipeline.add_component("retriever", InMemoryEmbeddingRetriever(document_store, top_k=3))
rag_pipeline.add_component("prompt_builder", ChatPromptBuilder(template=template))
rag_pipeline.add_component("generator", OpenAIChatGenerator(model="gpt-4o-mini"))
rag_pipeline.add_component("answer_builder", AnswerBuilder())
rag_pipeline.connect("query_embedder", "retriever.query_embedding")
rag_pipeline.connect("retriever", "prompt_builder.documents")
rag_pipeline.connect("prompt_builder.prompt", "generator.messages")
rag_pipeline.connect("generator.replies", "answer_builder.replies")
rag_pipeline.connect("retriever", "answer_builder.documents")
Asking a Question
When asking a question, use the run() method of the pipeline. Make sure to provide the question to all components that require it as input. In this case these are the query_embedder, the prompt_builder and the answer_builder.
question = "Do high levels of procalcitonin in the early phase after pediatric liver transplantation indicate poor postoperative outcome?"
response = rag_pipeline.run(
{
"query_embedder": {"text": question},
"prompt_builder": {"question": question},
"answer_builder": {"query": question},
}
)
print(response["answer_builder"]["answers"][0].data)
Evaluate the Pipeline
For this tutorial, let’s evaluate the pipeline with the following metrics:
- Document Mean Reciprocal Rank: Evaluates retrieved documents using ground truth labels. It checks at what rank ground truth documents appear in the list of retrieved documents.
- Semantic Answer Similarity: Evaluates predicted answers using ground truth labels. It checks the semantic similarity of a predicted answer and the ground truth answer using a fine-tuned language model.
- Faithfulness: Uses an LLM to evaluate whether a generated answer can be inferred from the provided contexts. Does not require ground truth labels.
Firt, let’s actually run our RAG pipeline with a set of questions, and make sure we have the ground truth labels (both answers and documents) for these questions. Let’s start with 25 random questions and labels 👇
📝 Some Notes:
- For a full list of available metrics, check out the Haystack Evaluators.
- In our dataset, for each example question, we have 1 ground truth document as labels. However, in some scenarios more than 1 ground truth document may be provided as labels. You will notice that this is why we provide a list of
ground_truth_documentsfor each question.
import random
questions, ground_truth_answers, ground_truth_docs = zip(
*random.sample(list(zip(all_questions, all_ground_truth_answers, all_documents)), 25)
)
Next, let’s run our pipeline and make sure to track what our pipeline returns as answers, and which documents it retrieves:
rag_answers = []
retrieved_docs = []
for question in list(questions):
response = rag_pipeline.run(
{
"query_embedder": {"text": question},
"prompt_builder": {"question": question},
"answer_builder": {"query": question},
}
)
print(f"Question: {question}")
print("Answer from pipeline:")
print(response["answer_builder"]["answers"][0].data)
print("\n-----------------------------------\n")
rag_answers.append(response["answer_builder"]["answers"][0].data)
retrieved_docs.append(response["answer_builder"]["answers"][0].documents)
While each evaluator is a component that can be run individually in Haystack, they can also be added into a pipeline. This way, we can construct an eval_pipeline that includes all evaluators for the metrics we want to evaluate our pipeline on.
from haystack.components.evaluators.document_mrr import DocumentMRREvaluator
from haystack.components.evaluators.faithfulness import FaithfulnessEvaluator
from haystack.components.evaluators.sas_evaluator import SASEvaluator
eval_pipeline = Pipeline()
eval_pipeline.add_component("doc_mrr_evaluator", DocumentMRREvaluator())
eval_pipeline.add_component("faithfulness", FaithfulnessEvaluator())
eval_pipeline.add_component("sas_evaluator", SASEvaluator(model="sentence-transformers/all-MiniLM-L6-v2"))
results = eval_pipeline.run(
{
"doc_mrr_evaluator": {
"ground_truth_documents": list([d] for d in ground_truth_docs),
"retrieved_documents": retrieved_docs,
},
"faithfulness": {
"questions": list(questions),
"contexts": list([d.content] for d in ground_truth_docs),
"predicted_answers": rag_answers,
},
"sas_evaluator": {"predicted_answers": rag_answers, "ground_truth_answers": list(ground_truth_answers)},
}
)
Constructing an Evaluation Report
Once we’ve run our evaluation pipeline, we can also create a full evaluation report. Haystack provides an EvaluationRunResult which we can use to display an aggregated_report 👇
from haystack.evaluation.eval_run_result import EvaluationRunResult
inputs = {
"question": list(questions),
"contexts": list([d.content] for d in ground_truth_docs),
"answer": list(ground_truth_answers),
"predicted_answer": rag_answers,
}
evaluation_result = EvaluationRunResult(run_name="pubmed_rag_pipeline", inputs=inputs, results=results)
evaluation_result.aggregated_report()
Extra: You can also see a detailed report with the scores for each sample in your dataset, and we will choose the output format as DataFrame
results_df = evaluation_result.detailed_report(output_format="df")
results_df
Having our evaluation results as a dataframe can be quite useful. For example, below we can use the pandas dataframe to filter the results to the top 3 best scores for semantic answer similarity (sas_evaluator) as well as the bottom 3 👇
import pandas as pd
top_3 = results_df.nlargest(3, "sas_evaluator")
bottom_3 = results_df.nsmallest(3, "sas_evaluator")
pd.concat([top_3, bottom_3])
What’s next
🎉 Congratulations! You’ve learned how to evaluate a RAG pipeline with model-based evaluation frameworks and without any labeling efforts.
If you liked this tutorial, you may also enjoy:
To stay up to date on the latest Haystack developments, you can sign up for our newsletter. Thanks for reading!