
Walkthrough: Evaluation
A guided walkthrough to learn everything about evaluation
Last Updated: June 15, 2026Evaluation measures performance using metrics like precision, recall, and relevancy, providing a clear picture of your pipeline’s strengths and weaknesses using LLMs or ground-truth labels.
Evaluating RAG systems can help understand performance bottlenecks and optimize one component at a time, for example, a Retriever or a prompt used with a Generator.
Here’s a step-by-step guide explaining what you need to evaluate, how you evaluate, and how you can improve your application after evaluation using Haystack!
1. Building your pipeline
Choose the required components based on your use case and create your Haystack pipeline. If you’re a beginner, start with 📚 Tutorial: Creating Your First QA Pipeline with Retrieval-Augmentation. If you’d like to explore different model providers, vector databases, retrieval techniques, and more with Haystack, pick an example from🧑🍳 Haystack Cookbooks.
2. Human Evaluation
As the first step, perform manual evaluation. Test a few queries (5-10 queries) and manually assess the accuracy, relevance, coherence, format, and overall quality of your pipeline’s output. This will provide an initial understanding of how well your system performs and highlight any obvious issues.
To trace the data through each pipeline step, debug the intermediate components using the include_outputs_from parameter. This feature is particularly useful for observing the retrieved documents or verifying the rendered prompt. By examining these intermediate outputs, you can pinpoint where issues may arise and identify specific areas for improvement, such as tweaking the prompt or trying out different models.
3. Deciding on Metrics
Evaluation metrics are crucial for measuring the effectiveness of your pipeline. Common metrics are:
- Semantic Answer Similarity: Evaluates the semantic similarity of the generated answer and the ground truth rather than their lexical overlap.
- Context Relevancy: Assesses the relevance of the retrieved documents to the query.
- Faithfulness: Evaluates to what extent a generated answer is based on retrieved documents
- Context Precision: Measures the accuracy of the retrieved documents.
- Context Recall: Measures the ability to retrieve all relevant documents.
Some metrics might require labeled data, while others can be evaluated using LLMs without needing labeled data. As you evaluate your pipeline, explore various types of metrics, such as statistical and model-based metrics, or incorporate custom metrics using LLMs with the LLMEvaluator.
| Retrieval Evaluation | Generation Evaluation | End-to-end Evaluation | |
|---|---|---|---|
| Labeled data | DocumentMAPEvaluator, DocumentMRREvaluator, DocumentRecallEvaluator | - | AnswerExactMatchEvaluator, SASEvaluator |
| Unlabeled data (LLM-based) | ContextRelevanceEvaluator | FaithfulnessEvaluator | LLMEvaluator** |
** You need to provide the instruction and the examples to the LLM to evaluate your system.
In addition to Haystack’s built-in evaluators, you can use metrics from other evaluation frameworks like ragas and DeepEval. For more detailed information on evaluation metrics, refer to 📖 Docs: Evaluation.
4. Building an Evaluation Pipeline
Build a pipeline with your evaluators. To learn about evaluating with Haystack’s own metrics, you can follow 📚 Tutorial: Evaluating RAG Pipelines.
🧑🍳 As well as Haystack’s own evaluation metrics, you can also integrate with a number of evaluation frameworks. See the integrations and examples below 👇
For step-by-step instructions, watch our video walkthrough 🎥 👇
For a comprehensive evaluation, make sure to evaluate specific steps in the pipeline (e.g., retrieval or generation) and the performance of the entire pipeline. To get inspiration on evaluating your pipeline, have a look at 🧑🏼🍳 Cookbook: Prompt Optimization with DSPy, which explains the details of prompt optimization and evaluation, or read 📚 Article: RAG Evaluation with Prometheus 2, which explores using open LMs to evaluate with custom metrics.
If you’re looking for a straightforward and efficient solution for RAG, consider using EvaluationHarness, introduced with Haystack 2.3 through
haystack-experimental. You can learn more by running the example 💻
Notebook: Evaluating RAG Pipelines with EvaluationHarness.
5. Running Evaluation
The objective of running evaluations is to measure your pipeline’s performance and detect any regressions. To track progress, it is essential to establish baseline metrics using off-the-shelf approaches such as BM25 for keyword retrieval or “sentence-transformers” models for embeddings. Then, continue evaluating your pipeline with various parameters: adjust the top_k value, experiment with different embedding models, tweak the temperature, and benchmark the results to identify what works best for your use case. If labeled data is needed for evaluation, you can use datasets that include ground-truth documents and answers. Such datasets are available on
Hugging Face datasets or in the
haystack-evaluation repository.
Ensure your evaluation environment is set up to facilitate easy testing with different parameters. The haystack-evaluation repository provides examples with various architectures against different datasets.
For more information on optimizing your pipeline by experimenting with different parameter combinations, refer to 📚 Article: Benchmarking Haystack Pipelines for Optimal Performance.
6. Analyzing Results
Visualize your data and your results to have a general understanding of your pipeline’s performance.
- Create a report using EvaluationRunResult.score_report() and transform the evaluation results into a Pandas DataFrame with the aggregated scores for each metric:
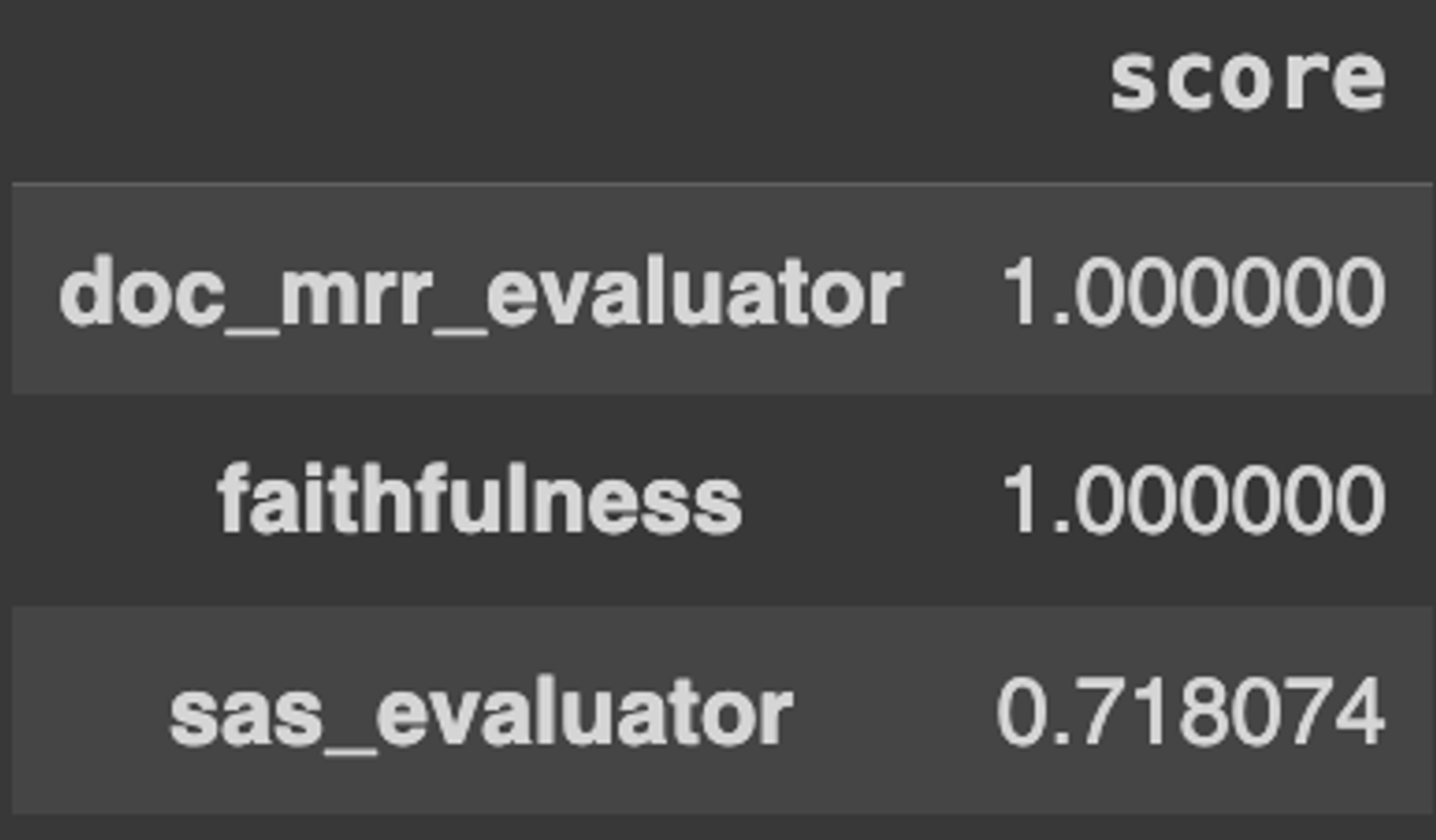
- Use Pandas to analyze the results for different parameters (
top_k,batch_size,embedding_model) in a comprehensive view - Use libraries like Matplotlib or Seaborn to visually represent your evaluation results.
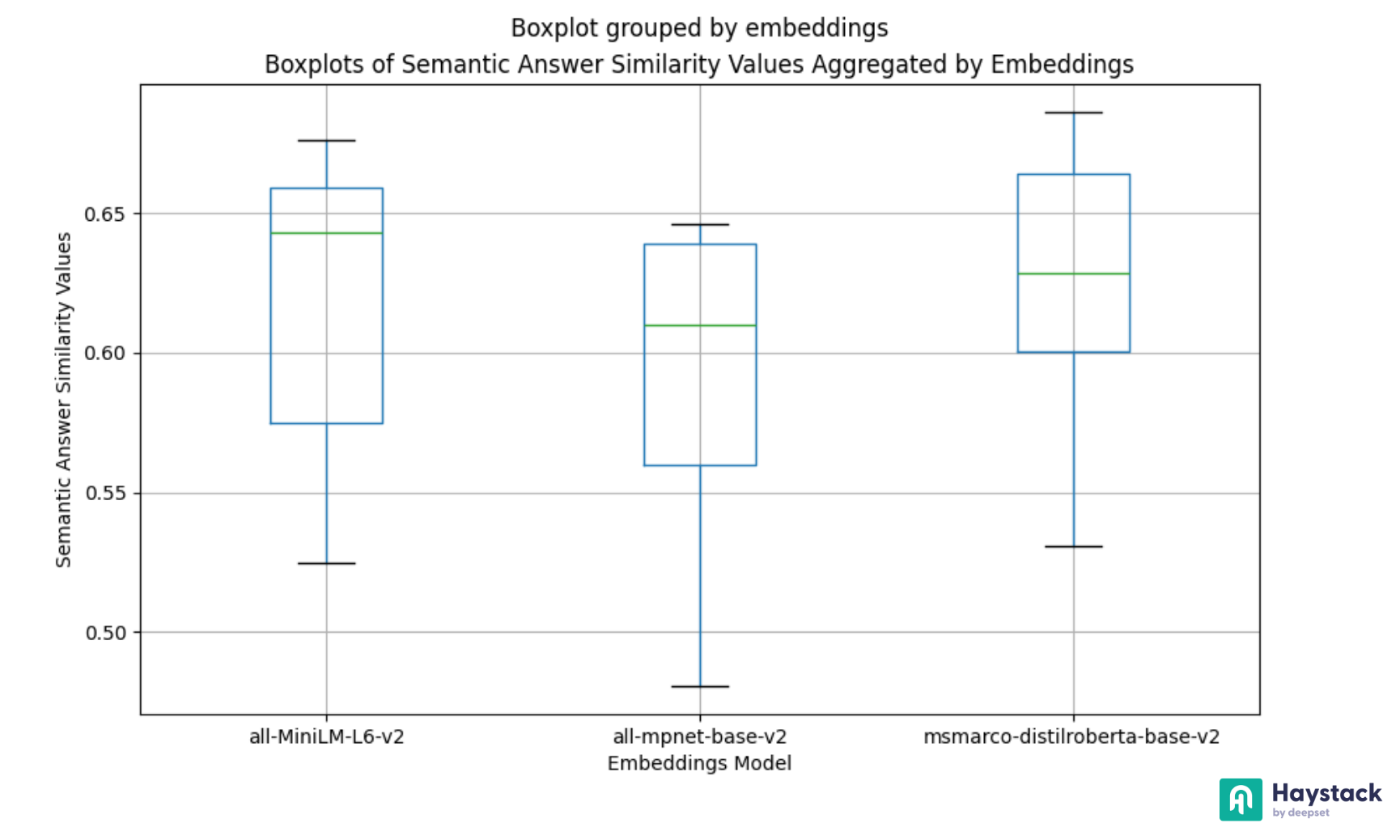
Refer to 📚 Benchmarking Haystack Pipelines for Optimal Performance: Results Analysis or 💻 Notebook: Analyze ARAGOG Parameter Search to visualize evaluation results.
7. Improving Your Pipeline
After evaluation, analyze the results to identify areas of improvement. Here are some methods:
Methods to Improve Retrieval:
- Data Cleaning: Ensure your data is clean and well-structured before indexing using DocumentCleaner and DocumentSplitter.
- Data Quality: Enrich the semantics of your documents by embedding meaningful metadata alongside the document’s contents.
- Metadata Filtering: Limit the search space by using metadata filters or extracting metadata from queries to use as filters. For more details, read 📚 Extract Metadata from Queries to Improve Retrieval.
- Different Embedding Models: Compare different embedding models from different model providers. See the full list of supported embedding providers in Embedders.
- Advanced Retrieval Techniques: Leverage techniques like hybrid retrieval, sparse embeddings, or Hypothetical Document Embeddings (HYDE).
Methods to Improve Generation:
- Ranking: Incorporate a ranking mechanism into your retrieved documents before providing the context to your prompt
- Order by similarity: Reorder your retrieved documents by similarity using cross-encoder models from Hugging Face with SentenceTransformersSimilarityRanker, Rerank models from Cohere with CohereRanker, or Rerankers from Jina with JinaRanker
- Increase diversity by ranking: Maximize the overall diversity among your context using sentence-transformers models with SentenceTransformersDiversityRanker to help increase the semantic answer similarity (SAS) in LFQA applications.
- Address the “Lost in the Middle” problem by reordering: Position the most relevant documents at the beginning and end of the context using LostInTheMiddleRanker to increase faithfulness.
- Different Generators: Try different large language models and benchmark the results. The full list of model providers is in Generators.
- Prompt Engineering: Use few-shot prompts or provide more instructions to enable the exact match.
8. Monitoring
Implement strategies for tracing the application post-deployment. By integrating LangfuseConnector into your pipeline, you can collect the queries, documents, and answers and use them to continuously evaluate your application. Learn more about pipeline monitoring in 📚 Article: Monitor and trace your Haystack pipelines with Langfuse.