
Multimodal Search with Gemini Embedding 2 in Haystack
Build multimodal search systems in Haystack using Gemini Embedding 2 to embed text, images, video, audio, and PDFs in a shared vector space.
March 10, 2026Embeddings are the backbone of modern AI applications, from semantic search and recommendation systems to Retrieval-Augmented Generation (RAG). However, most embedding models operate in a single modality, typically focusing only on textual data.
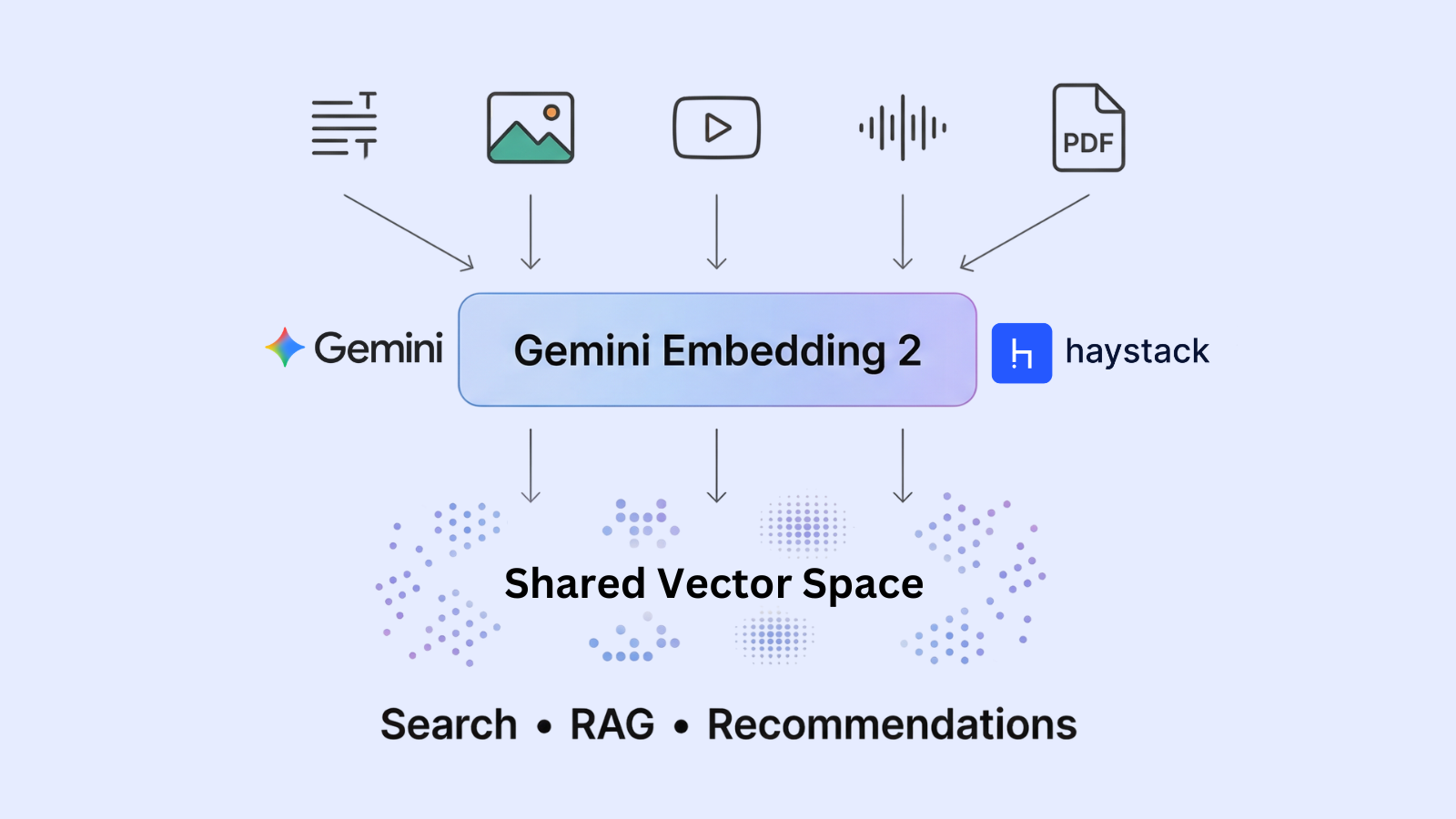
Google has introduced Gemini Embedding 2, a fully multimodal embedding model that maps text, images, video, audio, and PDFs into a shared vector space. This means you can search across different types of data using a single embedding model: gemini-embedding-2.
Even better, Haystack supports Gemini Embedding 2 from Day 0. Through the Google GenAI x Haystack integration, you can immediately start using the model in your Haystack applications for both text and multimodal embeddings.
Let’s take a closer look.
Meet Gemini Embedding 2
Gemini Embedding 2 is Google’s first fully multimodal embedding model, built on the Gemini architecture. It can map text, images, video, audio, and PDFs into a single unified vector space, enabling cross-modal comparison and retrieval using a shared semantic representation.
For example, a text query can retrieve relevant images, an audio clip can match a document, or a video segment can be retrieved using text search. This unified representation makes it easier to build multimodal applications like image search, recommendation systems, and RAG.
The model supports 100+ languages and allows developers to choose flexible embedding sizes using Matryoshka Representation Learning (MRL). Depending on the trade-off between storage and accuracy, you can select embedding dimensions up to 3072, with commonly recommended sizes being 768, 1536, or 3072 (default).
Gemini Embedding 2 also supports large inputs up to 8192 tokens, making it suitable for embedding longer documents and complex multimodal inputs.
Early benchmarks indicate strong performance across modalities, including a top-5 ranking on the MTEB Multilingual leaderboard for text and state-of-the-art results among proprietary models, with document retrieval performance comparable to Voyage.
Check out the official Google documentation for more details.
gemini-3.1-flash-image-preview aka. Nano Banana 2
Using Gemini Embeddings in Haystack
Haystack provides built-in components for generating Gemini embeddings through the Gemini API and Vertex AI.
For text data, you can use:
The GoogleGenAIDocumentEmbedder is typically used during the indexing to embed documents before storing them in a vector database.
# pip install haystack-ai google-genai-haystack
from datasets import load_dataset
from haystack import Document
from haystack.document_stores.in_memory import InMemoryDocumentStore
from haystack_integrations.components.embedders.google_genai import (
GoogleGenAIDocumentEmbedder, GoogleGenAITextEmbedder
)
document_store = InMemoryDocumentStore(embedding_similarity_function="cosine")
docs = [
Document(content="The capybara is the largest rodent in the world and is native to South America, where it lives near rivers, lakes, and wetlands. It is highly social and often seen relaxing in groups, spending much of its time swimming or soaking in water. Capybaras communicate through whistles, barks, and purr-like sounds."),
Document(content="Dogs are domesticated mammals known for their loyalty, intelligence, and strong bond with humans. They have been bred for thousands of years for roles such as companionship, hunting, guarding, and assisting people with various tasks. Different breeds vary widely in size, temperament, and abilities."),
Document(content="The tiger is the largest species of big cat and is recognized by its distinctive orange coat with black stripes. It is a powerful solitary predator that inhabits forests, grasslands, and wetlands across parts of Asia. Tigers are excellent swimmers and rely on stealth and strength to hunt prey."),
Document(content="The giraffe is the tallest land animal on Earth, easily identified by its long neck and distinctive spotted coat. It uses its height to reach leaves high in acacia trees and roams the savannas and open woodlands of Africa. Despite its long neck, a giraffe has the same number of neck vertebrae as most mammals."),
Document(content="Elephants are the largest land animals and are known for their intelligence, strong family bonds, and remarkable memory. They use their trunks for breathing, grasping objects, and communication. Elephants live in complex social groups led by a matriarch."),
Document(content="Penguins are flightless birds that live primarily in the Southern Hemisphere, especially in Antarctica. They are excellent swimmers, using their flipper-like wings to move through the water while hunting fish, squid, and krill."),
Document(content="Dolphins are highly intelligent marine mammals known for their playful behavior and complex communication. They live in social groups called pods and use echolocation to navigate and locate prey in the ocean."),
Document(content="Owls are nocturnal birds of prey with excellent night vision and silent flight. They hunt small mammals, insects, and other birds, relying on their sharp talons and keen hearing to detect prey in darkness."),
Document(content="Red pandas are small mammals native to the eastern Himalayas and southwestern China. They have reddish-brown fur, bushy tails, and spend most of their time in trees. Their diet mainly consists of bamboo, though they may also eat fruits and insects."),
Document(content="Kangaroos are large marsupials native to Australia and are famous for their powerful hind legs, large feet, and strong tails that help them balance while hopping. Female kangaroos carry and nurture their young, called joeys, in a pouch. They typically live in open grasslands and forests and often move in groups called mobs."),
]
doc_embedder = GoogleGenAIDocumentEmbedder(
model="gemini-embedding-2",
batch_size=5,
prefix="title: none | text: " # https://ai.google.dev/gemini-api/docs/embeddings#task-types
config={
"output_dimensionality": 768 # flexible embedding sizes using MRL
}
)
docs_with_embeddings = doc_embedder.run(docs)
document_store.write_documents(docs_with_embeddings["documents"])
Once documents are embedded and stored, you can embed queries using GoogleGenAITextEmbedder and retrieve relevant documents.
from haystack.components.retrievers.in_memory import InMemoryEmbeddingRetriever
from haystack_integrations.components.embedders.google_genai import GoogleGenAITextEmbedder
embedding_retriever = InMemoryEmbeddingRetriever(document_store=document_store)
query = "animal that communicates with whistles and barks"
text_embedder = GoogleGenAITextEmbedder(
model="gemini-embedding-2",
prefix="task: search result | query: " # https://ai.google.dev/gemini-api/docs/embeddings#task-types
config={
"output_dimensionality": 768 # flexible embedding sizes using MRL
}
)
query_embedding = text_embedder.run(query)["embedding"]
result = embedding_retriever.run(query_embedding=query_embedding, top_k=2)
for doc in result["documents"]:
print(doc.meta)
print(doc.content)
print(doc.score)
print("-" * 10)
In production applications, embeddings can be stored in search engines such as Qdrant, Elasticsearch or OpenSearch.
Multimodal Embeddings
Haystack also provides Day-0 support for multimodal embeddings with the new
GoogleGenAIMultimodalDocumentEmbedder component.
This component enables embedding images, audio, video, and PDFs directly inside Haystack pipelines, making it straightforward to build applications that search across multiple media types.
Example:
from haystack_integrations.components.embedders.google_genai import GoogleGenAIMultimodalDocumentEmbedder
from haystack import Document
docs = [
Document(meta={"file_path": "kangaroo.mp4"}),
Document(meta={"file_path": "tiger.jpg"}),
Document(meta={"file_path": "sample.pdf"}),
Document(meta={"file_path": "kangaroo.jpg"}),
Document(meta={"file_path": "cat.jpg"})
]
doc_multimodal_embedder = GoogleGenAIMultimodalDocumentEmbedder(
model="gemini-embedding-2",
config={
"output_dimensionality": 768 # flexible embedding sizes using MRL
}
)
docs_with_embeddings = doc_multimodal_embedder.run(docs)
document_store.write_documents(docs_with_embeddings["documents"])
Cross-modal Retrieval
One powerful capability enabled by multimodal embeddings is cross-modal retrieval, retrieving one type of content using another modality as the query.
For example, you can perform image-to-text search, where an image is used as a query to retrieve relevant text documents. If a user uploads an image of a dog, the system could retrieve documents describing dog breeds, training tips, or animal behavior.
To perform image-to-text search, you first embed your text documents during indexing (as shown earlier using GoogleGenAIDocumentEmbedder). Then you embed the image as the query using the multimodal embedder.
Because all modalities share the same vector space, you can use this approach to support cross-modal retrieval in any direction, for example text-to-image, image-to-text, audio-to-video, or video-to-document search.
Example:
image_doc = Document(meta={"file_path": "another_kangaroo.jpg"})
image_embedder = GoogleGenAIMultimodalDocumentEmbedder(
model="gemini-embedding-2",
config={
"output_dimensionality": 768 # flexible embedding sizes using MRL
}
)
# Create the embedding for the image
image_embedding = image_embedder.run([image_doc])["documents"][0].embedding
# Find the most semantically similar texts, images, audio, video and PDFs in the vector database
results = embedding_retriever.run(query_embedding=image_embedding, top_k=3)["documents"]
for doc in results:
print(doc.content)
print(doc.score)
print("-" * 100)
With multimodal embeddings, you can build applications such as:
-
Multimodal search
Example: search a product catalog with a text query like “red running shoes with white soles” and retrieve both product images and descriptions.
-
Cross-modal retrieval
Search one type of media using another modality. For example, upload a photo of a monument to retrieve relevant articles describing it.
-
Multimodal RAG systems
Combine documents, diagrams, screenshots, and videos as sources of knowledge.
-
Media recommendation systems
Recommend videos or images based on textual descriptions.
To learn more about working with multimodal data in Haystack, check out the tutorial on Creating Vision + Text RAG Pipelines.
What’s Next
Gemini Embedding 2 makes it easier to build multimodal-aware retrieval systems without stitching together multiple embedding models.
With Haystack, you can already use both text and multimodal embeddings with Gemini Embedding 2. We’re excited to see what multimodal applications you build next.

