

Integration: Azure CosmosDB
Use Azure CosmosDB with Haystack
Table of Contents
Overview
Azure Cosmos DB is a fully managed NoSQL, relational, and vector database for modern app development. It offers single-digit millisecond response times, automatic and instant scalability, and guaranteed speed at any scale. It is the database that ChatGPT relies on to dynamically scale with high reliability and low maintenance. Haystack supports MongoDB and PostgreSQL clusters running on Azure Cosmos DB.
Azure Cosmos DB for MongoDB makes it easy to use Azure Cosmos DB as if it were a MongoDB database. You can use your existing MongoDB skills and continue to use your favorite MongoDB drivers, SDKs, and tools by pointing your application to the connection string for your account using the API for MongoDB. Learn more in the Azure Cosmos DB for MongoDB documentation.
Azure Cosmos DB for PostgreSQL is a managed service for PostgreSQL extended with the Citus open source superpower of distributed tables. This superpower enables you to build highly scalable relational apps. You can start building apps on a single node cluster, as you would with PostgreSQL. As your app’s scalability and performance requirements grow, you can seamlessly scale to multiple nodes by transparently distributing your tables. Learn more in the Azure Cosmos DB for PostgreSQL documentation.
Installation
It’s possible to connect to your MongoDB cluster on Azure Cosmos DB through the MongoDBAtlasDocumentStore. For that, install the mongo-atlas-haystack integration.
pip install mongodb-atlas-haystack
If you want to connect to the PostgreSQL cluster on Azure Cosmos DB, install the pgvector-haystack integration.
pip install pgvector-haystack
Usage (MongoDB)
To use Azure Cosmos DB for MongoDB with MongoDBAtlasDocumentStore, you’ll need to set up an Azure Cosmos DB for MongoDB vCore cluster through the Azure portal. For a step-by-step guide, refer to
Quickstart: Azure Cosmos DB for MongoDB vCore.
After setting up your cluster, configure the MONGO_CONNECTION_STRING environment variable using the connection string for your cluster. You can find the connection string by following the instructions
here. The format should look like this:
import os
os.environ["MONGO_CONNECTION_STRING"] = "mongodb+srv://<username>:<password>@<clustername>.mongocluster.cosmos.azure.com/?tls=true&authMechanism=SCRAM-SHA-256&retrywrites=false&maxIdleTimeMS=120000"
Next, navigate to the Quickstart page of your cluster and click “Launch Quickstart.”
This will start the Quickstart guide, which will walk you through creating a database and a collection.
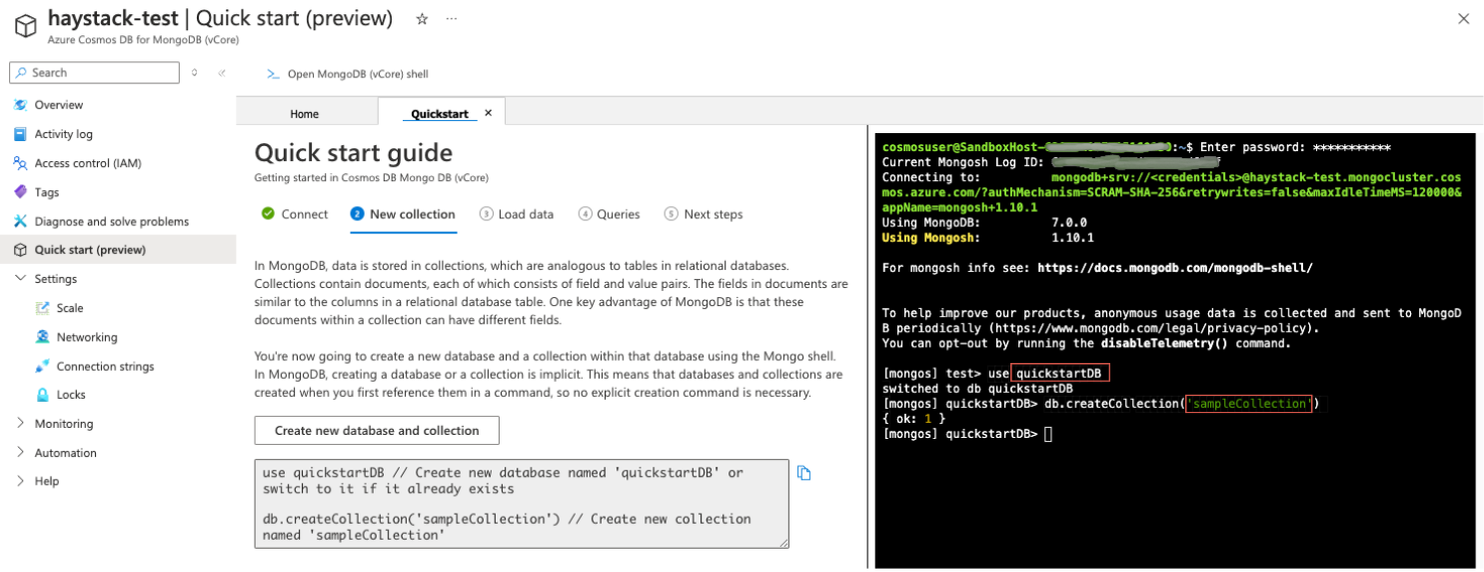
Once this is done, you can initialize the
MongoDBAtlasDocumentStore in Haystack with the appropriate configuration.
from haystack_integrations.document_stores.mongodb_atlas import MongoDBAtlasDocumentStore
from haystack import Document
document_store = MongoDBAtlasDocumentStore(
database_name="quickstartDB", # your db name
collection_name="sampleCollection", # your collection name
vector_search_index="haystack-test", # your cluster name
)
document_store.write_documents([Document(content="this is my first doc")])
Now, you can go ahead and build your Haystack pipeline using MongoDBAtlasEmbeddingRetriever. Check out the
MongoDBAtlasEmbeddingRetriever docs for the full pipeline example.
Usage (PostgreSQL)
To use Azure Cosmos DB for PostgreSQL with PgvectorDocumentStore, you’ll need to set up a PostgreSQL cluster through the Azure portal. For a step-by-step guide, refer to
Quickstart: Azure Cosmos DB for PostgreSQL.
After setting up your cluster, configure the PG_CONN_STR environment variable using the connection string for your cluster. You can find the connection string by following the instructions
here. The format should look like this:
import os
os.environ['PG_CONN_STR'] = "host=c-<cluster>.<uniqueID>.postgres.cosmos.azure.com port=5432 dbname=citus user=citus password={your_password} sslmode=require"
Once this is done, you can initialize the
PgvectorDocumentStore in Haystack with the appropriate configuration.
document_store = PgvectorDocumentStore(
table_name="haystack_documents",
embedding_dimension=1024,
vector_function="cosine_similarity",
search_strategy="hnsw",
recreate_table=True,
)
Now, you can go ahead and build your Haystack pipeline using PgvectorEmbeddingRetriever and PgvectorKeywordRetriever. Check out the
PgvectorEmbeddingRetriever docs for the full pipeline example.